Workflow
In my data science career, one major technical milestone (after learning how to code and adopt Git) was learning Docker and starting to use it. It opened a new world of opportunities, from automating processes to deploying data science work in production. This section defines what Docker is and the data science applications and use cases.
What is Docker?
Docker is a CI/CD tool that enables seamless code deployment from development to production environments. By creating OS-level virtualization, it can package an application and its dependencies in a virtual container and ship it between different environments. The main advantages of using Docker within your development environment are:
- Reproducibility - Docker enables you to seamlessly package your code and its dependencies into a single container and execute, test, share, and deploy it with a high level of consistency
- Collaboration - Docker solves the dependencies madness when a team of developers works together on a specific project. Having a unified environment saves a ton of time during the development step. For example, if one developer gets some error, it is easy for other developers to reproduce the error and help debug it
- Deployment - Docker simplifies the code shipment from the development environment to the production
Docker for Data Science
Docker was built to solve a common DevOps problem - the lack of reproducibility when shifting code between different environments (e.g., dev to prod). Reproducibility is not limited to DevOps, and it plays a critical role in the field of data science. We can define reproducibility as the ability to generate the exact outcome when running the same code regardless of the user or machine on which the code is running.
The first time I heard the term reproducibility was during my bachelor’s degree, where I learned that reproducibility starts and ends by setting a seed number to lock down random numbers. My favorite seed number is 12345. When I started to work as a data scientist, I realized that reproducibility goes beyond setting a seed number. Here are the main elements that can impact code reproducibility:
- Version control — First and foremost, reproducing the same results starts with the ability to track changes in your code Randomization — Controlling the random generation of numbers by setting the seed number
- Software version — The versions of your Python or R (or any other programming language) and its dependencies (e.g., libraries) impact the outcome of your code. For example, code that was built with pandas v1.0 may not run on v2.0 due to deprecation of functions
- Operating System (OS) — Most programming languages, particularly R and Python, use different compilers (e.g., C, C++, etc.) and other built-in OS components. The type of OS and its version could impact the outcome of your code
- Hardware — Last but not, the type of hardware (or infrastructure) could impact your results (ARM/Intel/Apple processor, etc)
In a regular data science workflow, reproducibility is dependent on several factors. One of the most basic and trivial elements of reproducibility is code versioning. Using unversioned code makes it impossible to track changes in your code or verify that the same code runs on different environments.
Another critical factor is package versioning. Over time, packages and their dependencies tend to change and evolve, get new features, bug fixes, replace and deprecate old functions. In some cases, running your code using a specific package version may not work or yield the same results as older or newer versions of the package. For example, code written with Pandas 1.x may not work with Pandas 2.x, and vice versa.
Similarly, programming languages tend to change over time, and using code built with older versions may not work or be supported with recent ones. Moreover, different operating systems use different software architectures or run different types of compilers (c, c++, etc.) on the backend. This difference may impact the reproducibility of your code.
Lastly, the type of CPU architecture (ARM, Intel, Apple Silocon, etc.) may impact the underlying software. Some packages or software may require a separate build or may not be supported, which can ultimately affect the reproducibility of your code.
Below is Figure 1, which illustrates the factors affecting code reproducibility when transferring between different environments.
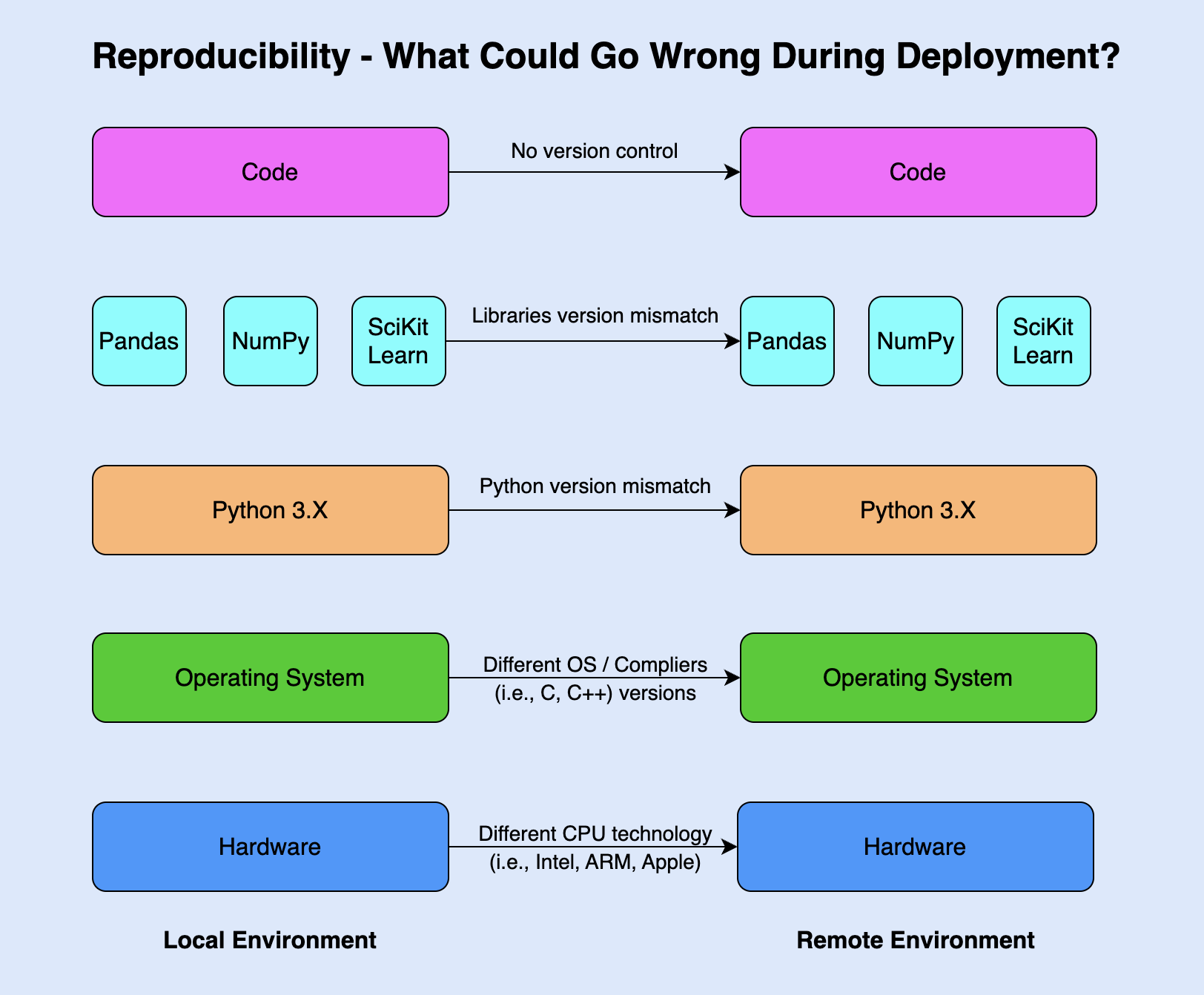
Git provides a solution for versioning and monitoring code, ensuring that it can be reproduced correctly regardless of the user or machine it runs on, as long as it is used properly. Docker and similar solutions address the problem of environment mismatches by creating an isolated environment within a container that can be shipped along with the code to any remote machine, such as a desktop, laptop or server, allowing for seamless reproduction of the process.
While developing software on different hardware architectures, such as Apple Silicon and Intel-based machines, there may be potential differences in the environment. Docker can partially address this issue by creating a dedicated image for each CPU architecture. However, this approach can be time-consuming and expensive since additional tests are required to ensure that all containers have the exact same characteristics.
Figure 2 demonstrates a general workflow with Docker and Git. We use Git and Github/Gitlab/Bitbucket (or any similar service) to code version control. Docker is used to set up a containerized environment, which will be used for code development and testing. We then shift our code with the container to any remote environment that supports containers (i.e., Github Actions, AWS, GCP, etc.).
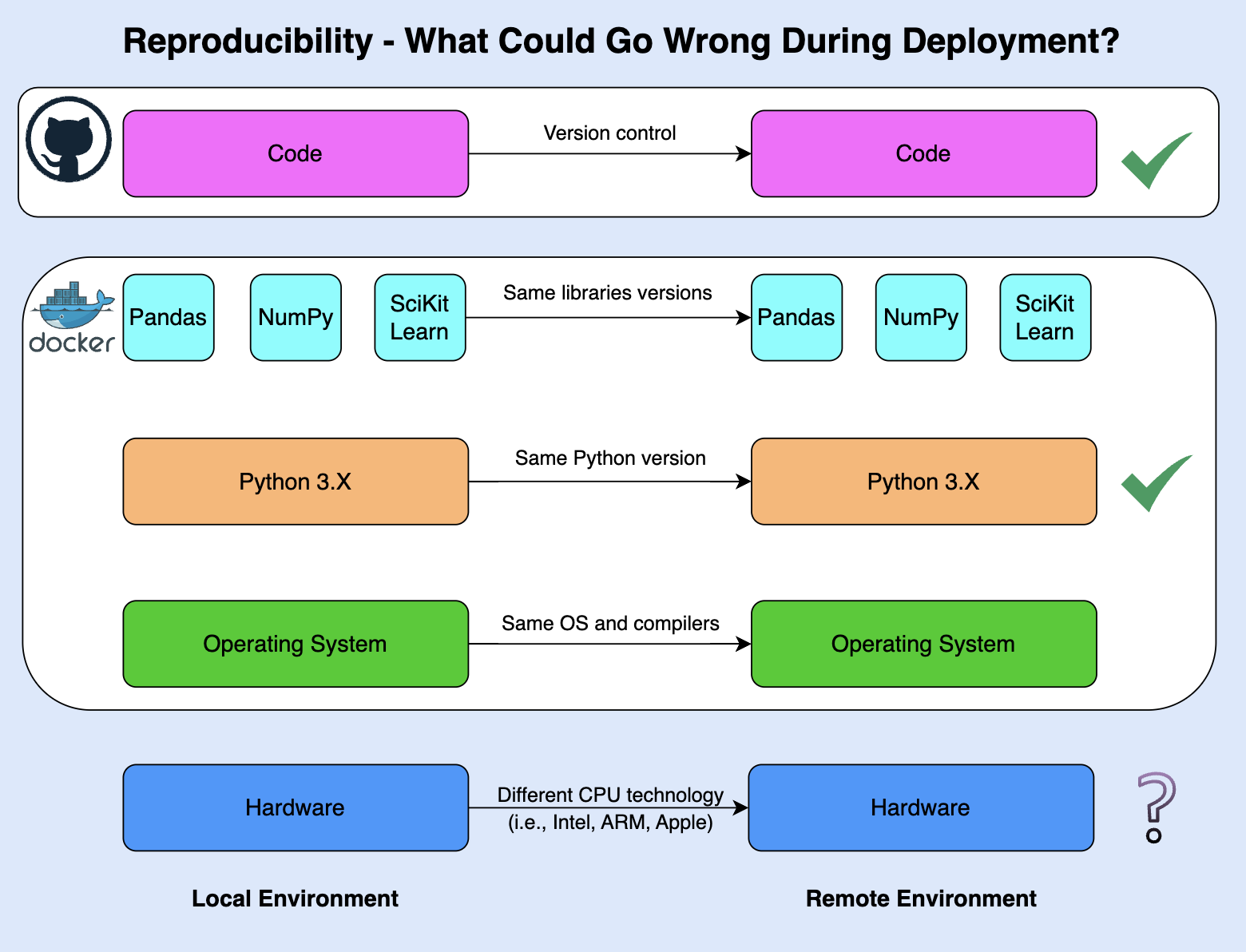
While this workflow provides a high level of reproducibility, it does not cover reproducibility issues you may encounter due to different hardware settings. There are different methods to address this issue, such as building a dedicated environment for each hardware architecture.
Note: Using a virtual environment is not an alternative to Docker. It actually works well together. While VE is not in the scope of this tutorial, you can read more about the differences between VE and Docker in the following article.